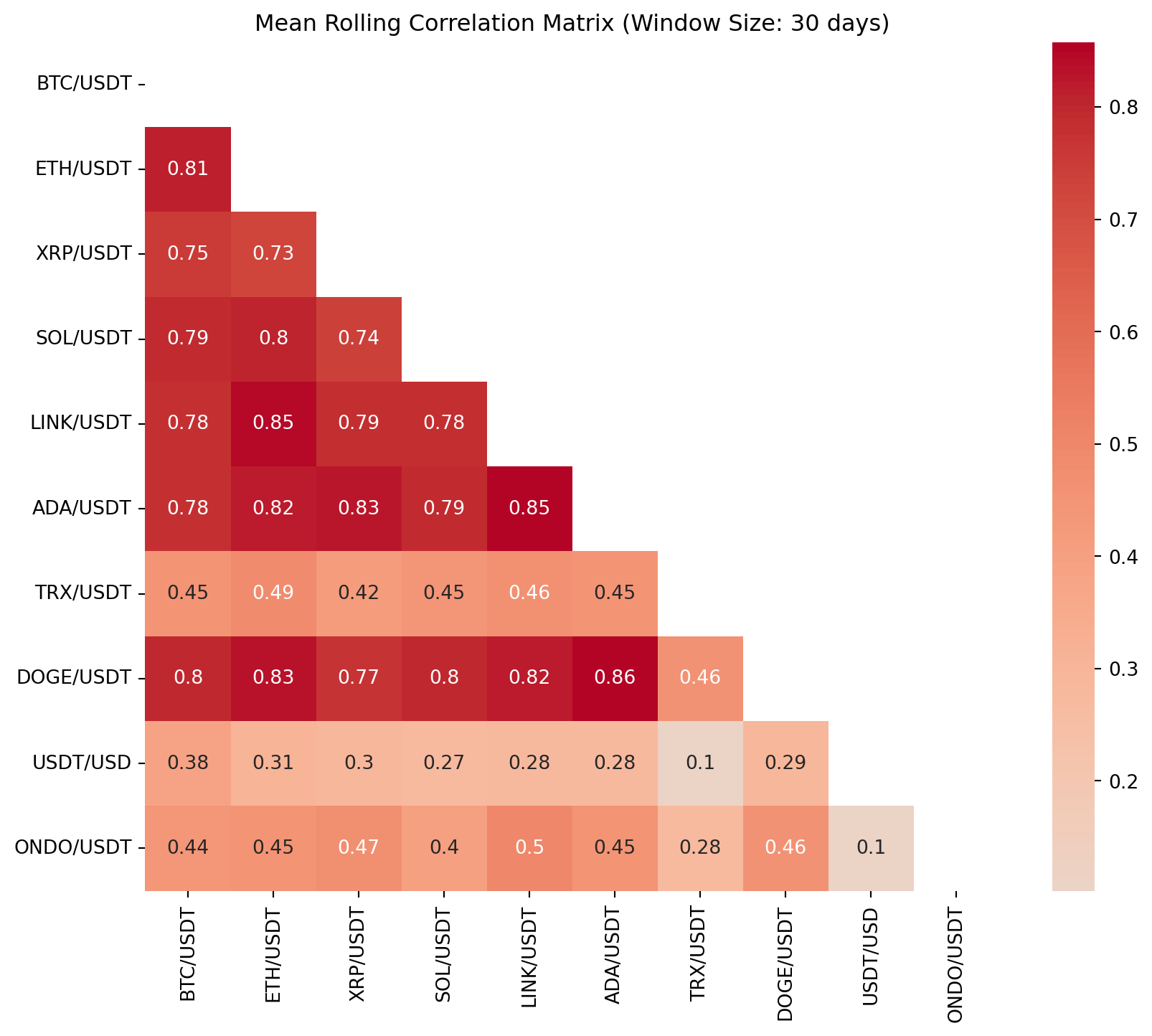
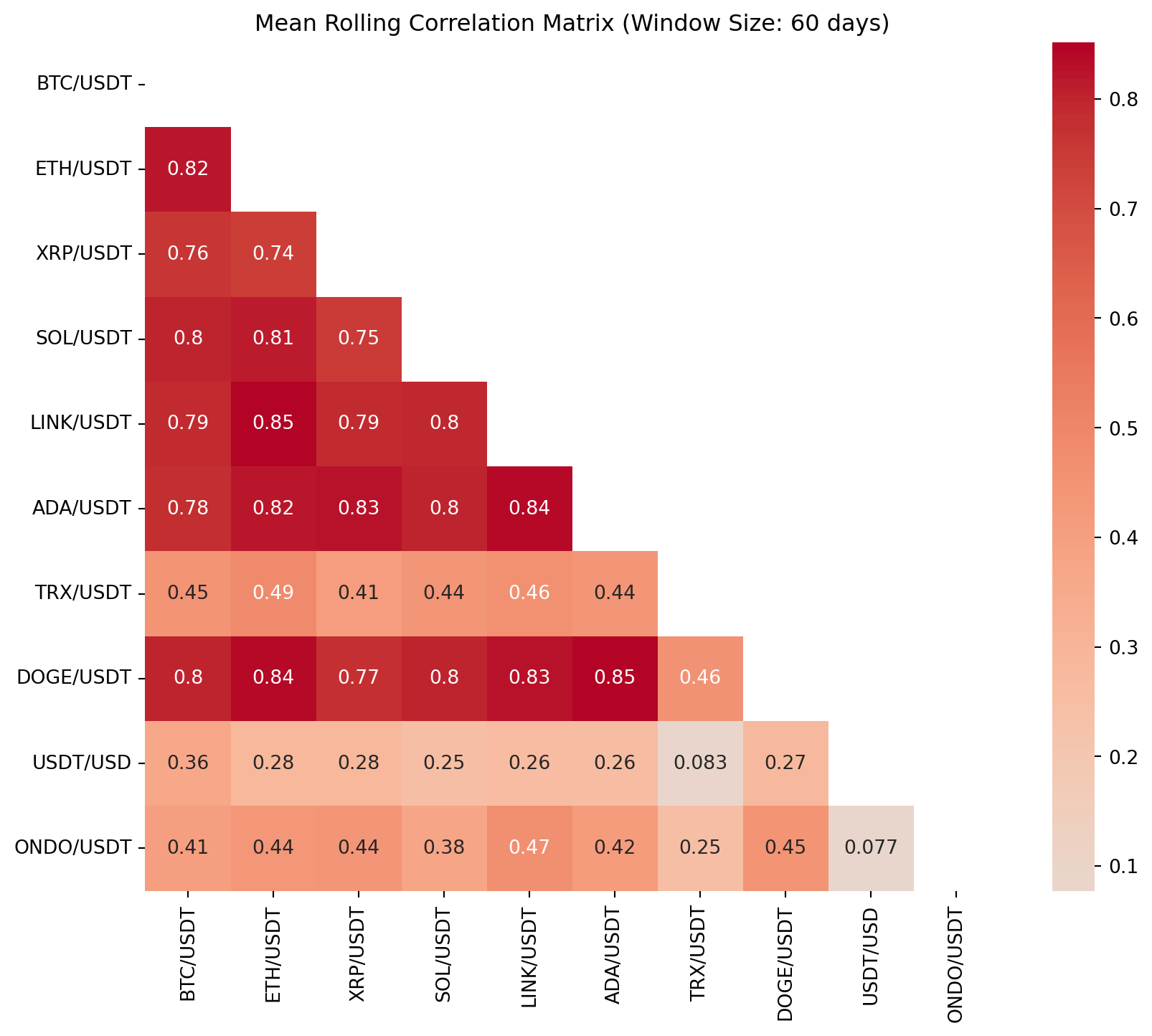
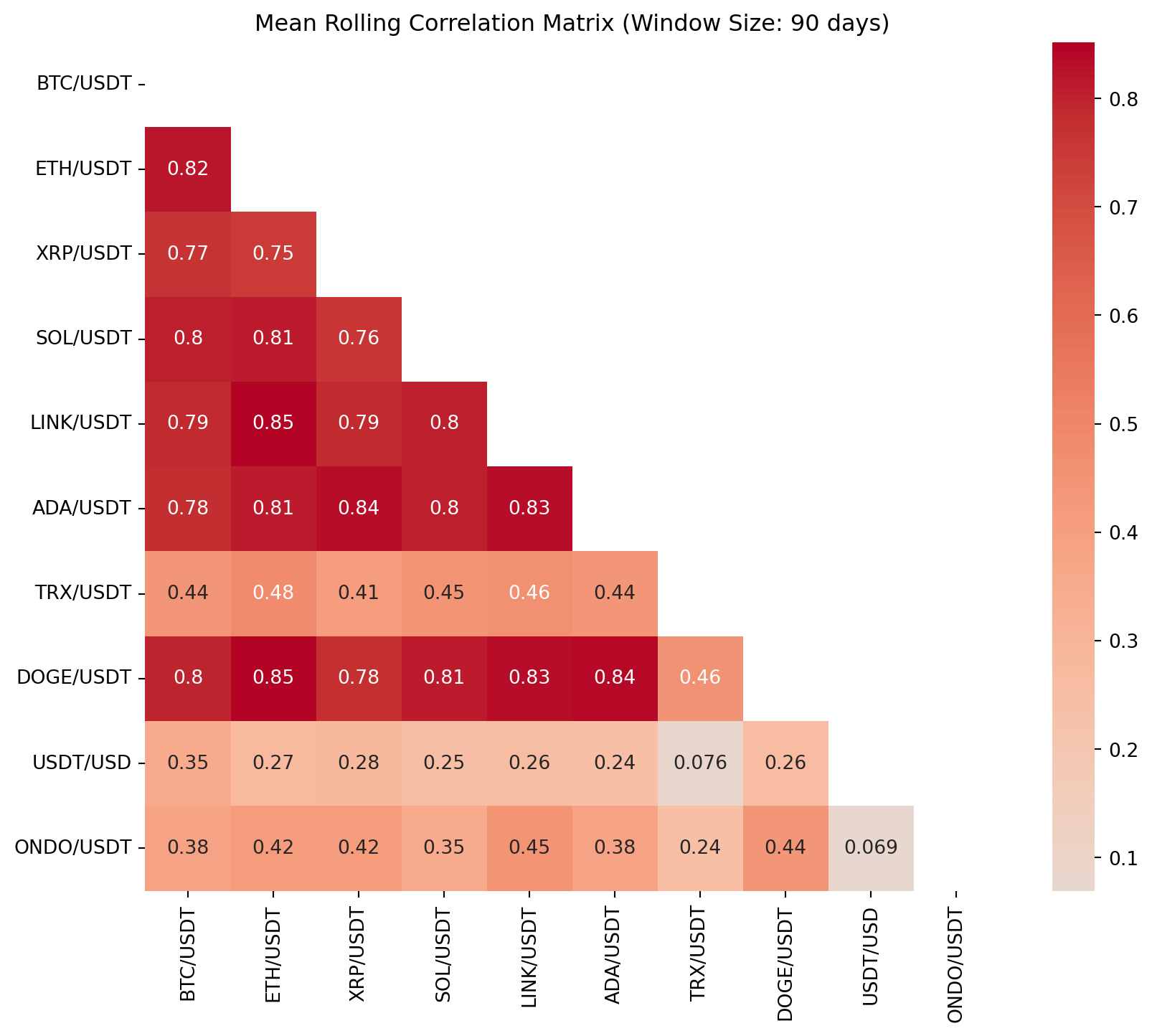
# 분석 결과 (Results)
# 여러 거래소에서 지원하는 거래쌍을 확인
import ccxt
import pandas as pd
# 주요 암호화폐 목록
TICKER_COIN = ['BTC/USDT', 'ETH/USDT', 'USDT/USD', 'XRP/USDT', 'SOL/USDT', 'LINK/USDT', 'ONDO/USDT', 'ADA/USDT', 'TRX/USDT', 'DOGE/USDT']
# 지원하는 거래소 목록
exchanges = ['binance', 'kraken', 'bitfinex', 'poloniex']
# 각 거래소에서 지원하는 거래쌍 확인
for exchange_id in exchanges:
exchange = getattr(ccxt, exchange_id)()
markets = exchange.load_markets()
supported_pairs = [pair for pair in TICKER_COIN if pair in markets]
print(f"{exchange_id} supports: {supported_pairs}")
# 주요 암호화폐 목록
binance_tickers = ['BTC/USDT', 'ETH/USDT', 'XRP/USDT', 'SOL/USDT', 'LINK/USDT', 'ADA/USDT', 'TRX/USDT', 'DOGE/USDT']
kraken_tickers = ['USDT/USD']
poloniex_tickers = ['ONDO/USDT']
# 데이터 기간 설정
START_DATE = '2024-03-01'
END_DATE = '2025-02-28'
# 거래소 설정
binance = ccxt.binance()
kraken = ccxt.kraken()
poloniex = ccxt.poloniex()
# 데이터 불러오기 함수
def fetch_crypto_data(exchange, tickers, start, end):
data = {}
start_timestamp = exchange.parse8601(f'{start}T00:00:00Z')
end_timestamp = exchange.parse8601(f'{end}T00:00:00Z')
for ticker in tickers:
try:
ohlcv = exchange.fetch_ohlcv(ticker, '1d', since=start_timestamp, limit=1000)
df = pd.DataFrame(ohlcv, columns=['timestamp', 'open', 'high', 'low', 'close', 'volume'])
df['timestamp'] = pd.to_datetime(df['timestamp'], unit='ms')
df.set_index('timestamp', inplace=True)
data[ticker] = df['close']
except Exception as e:
print(f"Error fetching {ticker} from {exchange.id}: {e}")
return pd.DataFrame(data)
# 데이터 불러오기
binance_data = fetch_crypto_data(binance, binance_tickers, START_DATE, END_DATE)
kraken_data = fetch_crypto_data(kraken, kraken_tickers, START_DATE, END_DATE)
poloniex_data = fetch_crypto_data(poloniex, poloniex_tickers, START_DATE, END_DATE)
# 모든 데이터를 하나의 DataFrame으로 병합
crypto_prices = pd.concat([binance_data, kraken_data, poloniex_data], axis=1)
# 1) 일간 수익률 계산
def compute_returns(price_data: pd.DataFrame) -> pd.DataFrame:
return price_data.pct_change().dropna(how='all')
crypto_returns = compute_returns(crypto_prices)
# 2) 롤링 상관계수 계산
def rolling_correlation(returns: pd.DataFrame, window: int) -> pd.DataFrame:
"""
returns: (date x tickers) DataFrame
window: rolling window size (days)
returns.rolling(window).corr() 결과는
- MultiIndex (date, ticker1)
- columns = ticker2
형태를 가집니다.
"""
corr_rolling = returns.rolling(window).corr()
return corr_rolling
# 3) 날짜별 상관행렬을 모아서 평균 상관행렬을 산출
def average_correlation_matrix(returns: pd.DataFrame, window: int) -> pd.DataFrame:
"""
- returns.rolling(window).corr() 결과를 사용
- 각 날짜별 (티커 x 티커) 상관행렬을 합산 후, 날짜 개수로 나누어 평균
"""
corr_rolling = rolling_correlation(returns, window)
# MultiIndex에서 날짜(level=0) 목록을 추출
unique_dates = corr_rolling.index.get_level_values(0).unique()
tickers = returns.columns
# 상관행렬 누적 합을 위한 (티커 x 티커) 형태의 빈 DataFrame
sum_matrix = pd.DataFrame(0.0, index=tickers, columns=tickers)
count = 0
for date in unique_dates:
# (ticker1 x ticker2) 형태를 얻기 위해 xs(date, level=0)
date_corr = corr_rolling.xs(date, level=0)
# date_corr.index = ticker1, date_corr.columns = ticker2
# 혹시 일부 티커에 대한 데이터가 누락되었을 경우를 대비하여 reindex
date_corr = date_corr.reindex(index=tickers, columns=tickers)
# 날짜별 상관행렬(N x N)을 모두 누적
if date_corr.notna().all().all():
sum_matrix += date_corr.fillna(0.0)
count += 1
# 평균 계산 (count가 0이 되지 않는다고 가정)
mean_matrix = sum_matrix / count
return mean_matrix
# 4) 롤링 상관계수 평균 계산
rolling_corr_results = {}
for window in [30, 60, 90]:
mean_corr_matrix = average_correlation_matrix(crypto_returns, window)
rolling_corr_results[window] = mean_corr_matrix